
Uncertainty-aware Knowledge Tracing
Uncertainty-aware Knowledge Tracing
发表日期:2025年1月9日
Paper
简单描述
以往的研究通常采用确定性表示来捕捉学生知识状态,忽略了学生交互过程中的不确定性,因此无法准确建模学习过程中的真实知识状态。
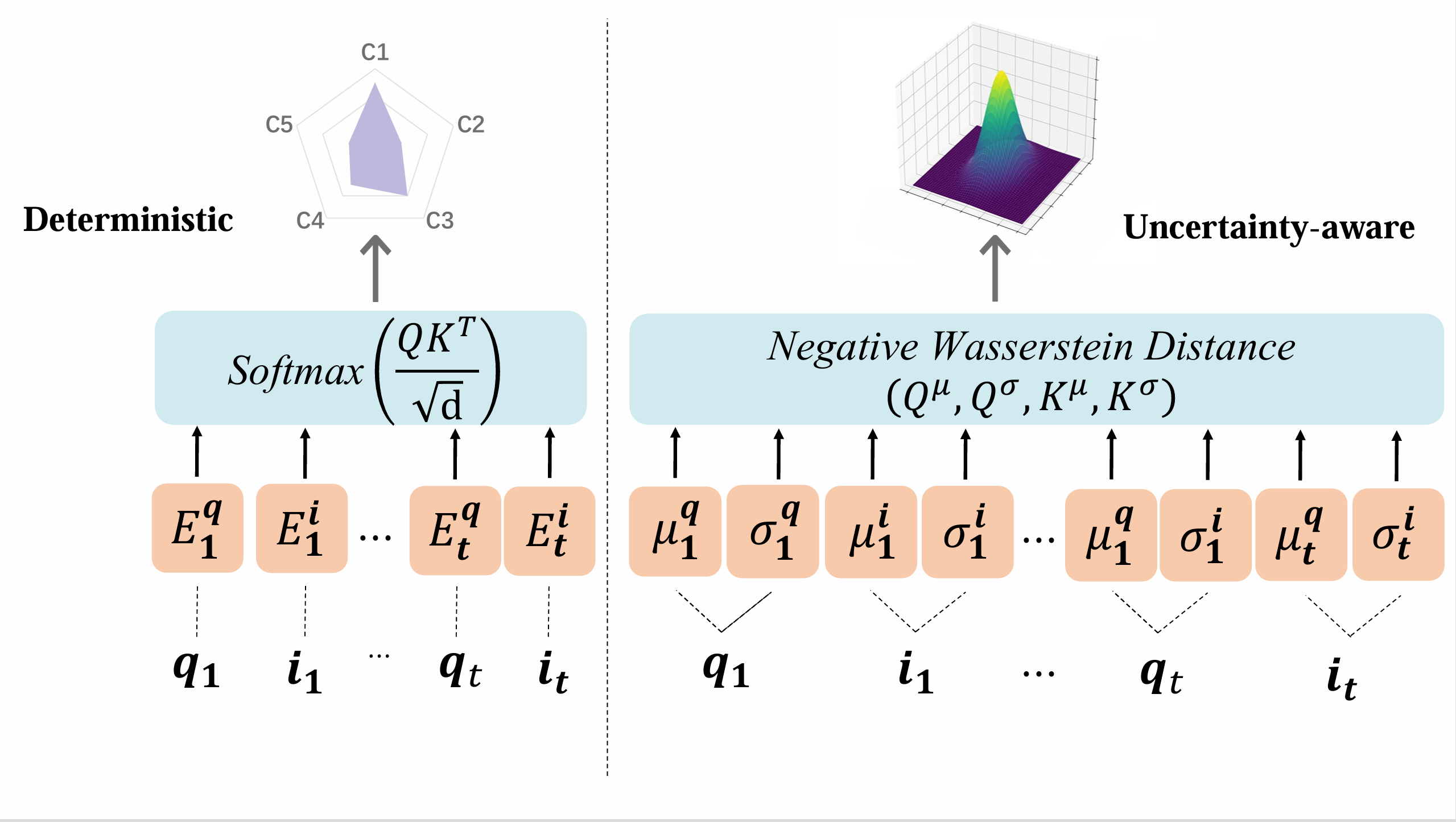
本文提出了一个不确定性感知知识追踪模型(UKT) ,该模型采用随机分布嵌入来表示学生交互中的不确定性,并设计了一种基于Wasserstein的自注意力机制,用于捕捉学生学习行为中状态分布的转换。此外,我们引入了一种随机不确定性感知对比学习损失,增强了模型对不同类型不确定性的鲁棒性。
| 不确定性类型 | 定义 | 影响与作用 |
|---|---|---|
| 认知不确定性 (Epistemic Uncertainty) |
与模型或数据的不完全性相关,反映了对真实知识状态的不确定程度 | 有助于更准确地评估学生的真实知识水平 |
| 随机不确定性 (Aleatory Uncertainty) |
与随机因素相关,例如学生的偶然失误或幸运猜测 | 可能会误导模型评估 |
问题陈述
对于每个学生 S,我们假设我们有一系列按时间顺序排列的 T 个交互,即 。每个交互可以表示为一个结构化的四元组 ,其中 是具体的问题, 是与问题相关联的知识点集合, 是学生的二元响应(正确或错误), 是学生回答的时间点。我们的目标是基于此信息构建一个模型,以评估和预测学生正确回答给定问题 的概率 。
Methodology
UKT模型使用一个随机嵌入层,通过均值和协方差参数将学生交互表示为高斯分布。其中,均值表示学生的基础知识水平,而协方差则捕捉学习过程中的不确定性,包括认知不确定性和随机不确定性。
基于Wasserstein距离的自注意力层分析这一高斯分布,以追踪知识状态的变化。
随后,学生的知识状态及其相关不确定性通过一个前馈神经网络(Feed-Forward Network, FFN)层进行处理,以评估学生对特定问题的掌握程度和不确定性。
为了应对随机不确定性,我们引入了一个随机不确定性感知对比学习层,以增强模型预测的鲁棒性。
最后,我们将调整后的不确定性与学生的基础知识水平相结合,以预测其在特定问题上的表现。
Stochastic Embedding Layers(随机嵌入层)
从(Ghosh, Heffernan, Lan 2020)和(Liu et al. 2022)开发了我们的UKT。
Liu, Z.; Liu, Q.; Chen, J.; Huang, S.; Tang, J.; and Luo, W. 2022.pyKT: a python library to benchmark deep learning based knowledge tracing models.Advances in Neural Information Processing Systems, 35: 18542–18555.
Ghosh, A.; Heffernan, N.; and Lan, A. S. 2020.Context-aware attentive knowledge tracing.In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2330–2339.
随机嵌入层
- 首先将学生对问题的回答映射到KCs上,分别评估每个KC以评估理解。
- 然后,使用均值嵌入 来表示基础交互,并使用协方差嵌入 来表示不确定性,创建一个多维椭圆高斯分布来描述学生行为。
- 对知识组件(KCs)也应用相同的方法来获得 和 。
基于Wasserstein的自我注意力
-
为了解决点积无法衡量分布间差异的问题,引入了Wasserstein距离来跟踪学生学习状态在随机嵌入中的进展。
-
使用不同的位置嵌入来分别表示均值和协方差,记为 和 。
-
将位置嵌入添加到均值和协方差嵌入中,以获得调整后的均值 和 以及 和 。
-
推导了学生交互的均值和协方差序列嵌入,并推导了知识点(Knowledge Components,简称KCs)序列的均值和协方差嵌入,以与交互分布对齐。
-
应用注意力权重作为负的2-Wasserstein距离 来检索知识状态。
前馈网络(Feed-Forward Network)
使用两层全连接网络来细化知识状态。
随机不确定性感知对比学习(Aleatory Uncertainty-Aware Contrastive Learning)
构建了代表粗心行为和幸运猜测的负样本,用于对比学习。负交互序列表示为 。构建这样的语义负样本对于对比学习至关重要。具体来说,基于最后一个回答的问题的结果修改学生的交互序列。如果最后一个项目是正确的,我们反转所有先前正确的响应并保留最后一个正确的响应来构建负序列,以防止模型受到幸运猜测的影响。